Python 可视化爬虫数据处理,这是一个在数据挖掘和分析领域中备受关注的重要环节,在当今数字化的时代,从海量的网络数据中获取有价值的信息,并以直观清晰的方式呈现出来,对于许多开发者和研究人员来说具有极大的意义。
要成功处理 Python 可视化爬虫数据,关键在于理解和运用相关的技术和工具,需要选择适合的爬虫框架,Scrapy 或者 BeautifulSoup,它们能够有效地抓取网页数据,对于数据的清洗和预处理也是至关重要的步骤,这能去除噪声和无效数据,为后续的可视化打下坚实基础。

在数据处理过程中,数据的存储和管理同样不可忽视,可以使用数据库如 MySQL 或者 MongoDB 来保存抓取到的数据,以便随时进行查询和分析,而在可视化方面,Python 提供了丰富的库,如 Matplotlib、Seaborn 和 Plotly 等,能够将数据转化为生动形象的图表,如柱状图、折线图、饼图等,使数据的特征和趋势一目了然。
还需要注意数据的合法性和合规性,在进行爬虫操作时,务必遵守相关的法律法规和网站的使用规则,避免引发不必要的法律风险。
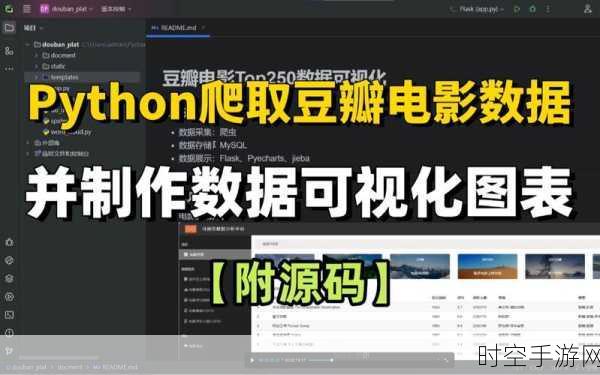
掌握 Python 可视化爬虫数据处理并非一蹴而就,需要不断学习和实践,熟练运用各种技术和工具,才能在数据的海洋中挖掘出有价值的宝藏,并以精彩的可视化方式呈现给用户。
参考来源:相关技术文档及行业经验分享
仅供参考,您可以根据实际需求进行调整和修改。