Hive Analyze 是大数据处理中至关重要的一环,优化其查询能够极大地提升数据处理的效率和性能。
在当今数据驱动的时代,高效的数据处理成为了企业和开发者追求的目标,Hive Analyze 作为常用的大数据分析工具,其查询优化至关重要。
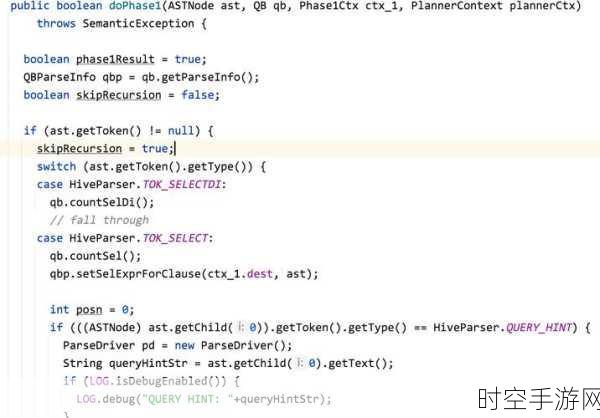
想要优化 Hive Analyze 的查询,理解其工作原理是基础,Hive Analyze 基于 Hadoop 生态系统,通过 MapReduce 框架进行数据处理,在这个过程中,数据的分布、存储格式以及计算资源的分配都会影响查询的性能。
优化查询的关键之一在于合理设置分区,通过对数据进行分区,可以减少数据扫描的范围,从而提高查询效率,按照时间、地域等常见维度进行分区,能够在查询特定条件的数据时,快速定位到相关分区,避免全表扫描。
索引的运用也是优化的重要手段,合适的索引能够加速数据的检索,但需要注意的是,过度创建索引可能会带来额外的维护成本和性能开销,因此需要根据实际的数据访问模式和频率来谨慎选择索引字段。
调整 Hive 的配置参数也能对查询性能产生显著影响,调整内存分配、并行度等参数,可以使 Hive 在处理查询时更好地利用系统资源,提高执行效率。
在实际应用中,还需要结合具体的业务需求和数据特点,综合运用以上多种优化策略,不断监测和分析查询的执行计划,以便及时发现潜在的性能瓶颈,并针对性地进行调整和优化。
掌握 Hive Analyze 的查询优化技巧,对于提升大数据处理的效率和质量具有重要意义,能够为企业和开发者带来更出色的数据处理能力和决策支持。
参考来源:大数据处理相关技术文档和实践经验。